In this blog, we'll explore how to set up a free AI code assistant for your development environment using Ollama and Continue. While GitHub Copilot and Cursor AI are popular choices now, there are times when you might prefer a local solution - whether for cost reasons or to keep your code private. We'll walk through setting up a powerful, free alternative that runs completely on your local machine.
Ollama is a tool which allows us to run AI models locally. We can either install it from the installer here or run as docker container using this image
Once installed you can verify by running the following command in your terminal:
ollama -v
Once you install Ollama, you can run many open source LLMs. You can find the list of available models here. To run a model, you can use the following command:
ollama run <model_name>
For example, to run the llama3.2 model, you can use:
ollama run llama3.2
There are many open source LLMs available. You can choose one based on your preference. Some popular ones are codelamma, wizardcoder, codeqwen etc. There are some leader boards also available like evalplus which can help you choose the best model for your use case. Also we need to consider the model size and the resources it consumes while running. Typically, a 7B model consumes around 8 GB of RAM.
Let us choose the codeqwen model for this blog which is a 7B model and start it by running the following command:
ollama run codeqwen
Initially it will take some time to download the model and start running it. Once it is ready, you will get a prompt like below where you can start chatting with the model.

In VS Code or Intellij IDEA go to extensions/plugins and search for Continue and install it.
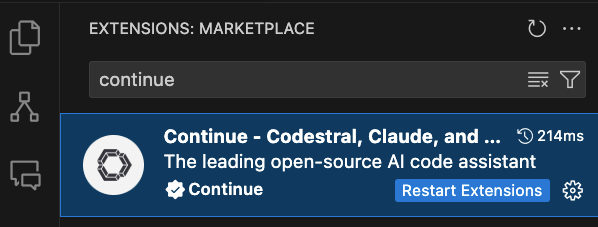
Once installed click on Continue icon on the left side. You will get a prompt to add a new model like below. Choose Provider as Ollama and select model as Autodetect. Click on Connect.
Once model is added codeqwen will be shown like below.

You can start chatting with the model by typing in the chat box.
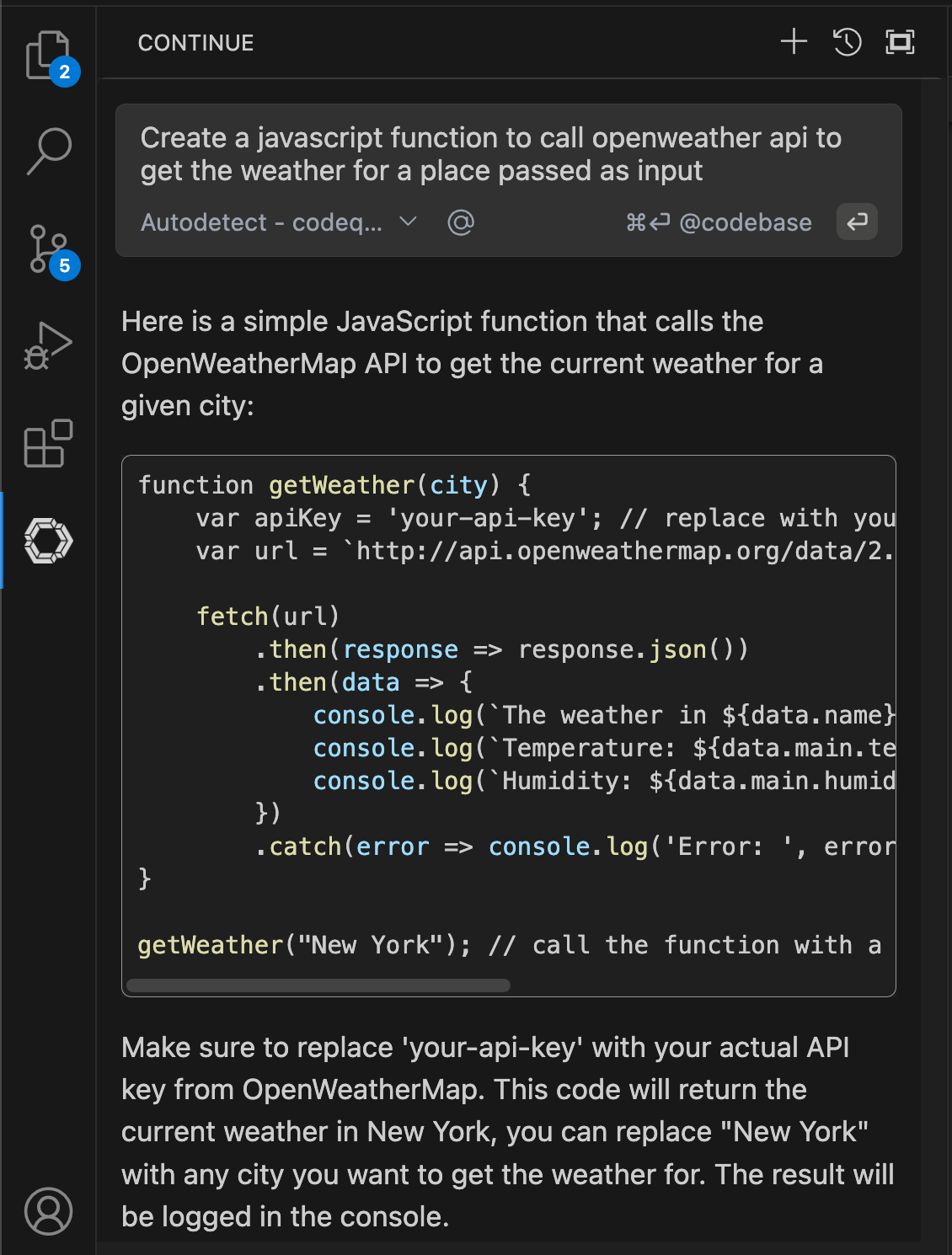
For code suggestions, first go to config.json in setting and add/update the below entry
"tabAutocompleteModel": { "title": "Tab Autocomplete Model", "provider": "ollama", "model": "codeqwen:latest", "apiKey": "" },
After that once you start typing in the code editor, you will get code suggestions from the model like below.

You can also do things like adding codebase, file etc. and asking for suggestion or explanation.
You can do the same in IntelliJ IDEA also by following the same steps.

Quality of the suggestions and the speed of the response was reasonably good during our testing. It was not as good as GitHub Copilot or Cursor AI but still it was good considering it is a free tool and runs locally in a normal laptop. If you can run a higher parameter model, you can improve the quality of the suggestions.
Local AI code assistants using Ollama and open source LLMs are a great way to enhance your coding experience without relying on cloud services. This local setup is particularly valuable for developers who need code privacy, work with sensitive data, or prefer a cost-effective alternative to cloud-based services. While AI code assistants are powerful tools, they can occasionally produce incorrect or inconsistent suggestions. Always review generated code carefully, validate its logic, and run comprehensive tests before incorporating it into your production codebase.
To stay updated with the latest updates in software engineering, follow us on linked in and medium.
Find the most popular YouTube creators in tech categories like AI, Java, JavaScript, Python, .NET, and developer conferences. Perfect for learning, inspiration, and staying updated with the best tech content.
Get instant AI-powered summaries of YouTube videos and websites. Save time while enhancing your learning experience.